





Elevate CX with unified, enterprise-grade listening
Sprinklr Insights gives you real-time consumer, competitor and market intelligence from 30+ channels without the noise. Make smarter decisions, strengthen your brand, and stay relentlessly customer-led.




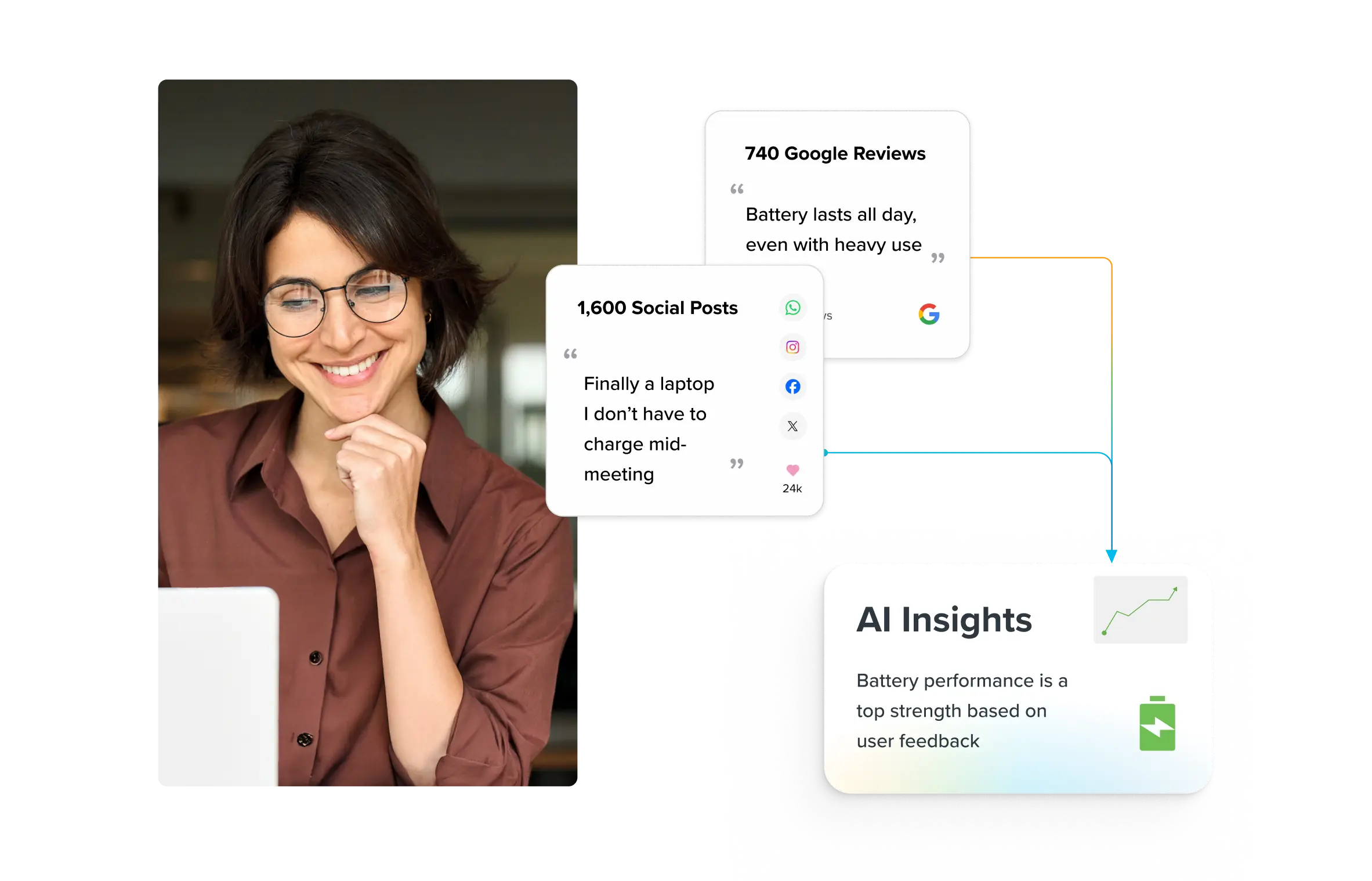
Text Analysis
What is text analysis?
Text analysis involves analyzing and processing text data to extract meaningful information. It can be done manually, by reading and interpreting the text, or it can be done computationally using various algorithms. Text analysis, when carried out computationally is referred to as text mining or text analytics.
Text analysis can be applied to all kinds of documents, including written documents, social media posts, customer reviews, and other forms of digital communication. It can be used to identify the sentiment, emotion, and meaning of text, as well as to classify and categorize it, extract key phrases and terms, and summarize and translate it. It is often used in a variety of business and research applications, such as customer sentiment analysis, content classification, and market research.
What's the difference between text analysis, text mining and natural language processing?
Text analysis, mining, and natural language processing (NLP) are terms that are often used interchangeably. However, there are some key differences:
- Text analysis is the process of examining and interpreting text in order to extract meaningful insights. It can involve both manual and computational methods.
- Text miningor text analytics is a subfield of text analysis that specifically involves computational algorithms to extract and analyze the data.
- Natural language processing (NLP) is a subfield of AI that involves the development of algorithms to understand, interpret, and generate human language. NLP algorithms are used for text analysis, but also have applicationsin language translation, and voice recognition.
The importance of text analysis
Text analysis has gained prominence over the previous years due to changing dynamics in industry:
- Unstructured text data is increasingly prevalent: text data is generated in large quantities through sources such as social media, customer reviews, and online articles.
- Text analysis can unravel patterns: algorithms can identify patterns in large datasets that might not be immediately obvious to humans. This is useful for understanding customer sentiment, identifying trends, and making data-backed decisions.
- Text analysis can improve efficiency: manually analyzing large volumes of data can be time-consuming and error-prone. Algorithms can automate the process, allowing organizations to extract insights more efficiently.
Text analysis use cases
Text analysis has a wide range of business applications, including:
- Customer sentiment analysis: Text analysis can help identify how customers feel about products or services. This can help identify strengths and weaknesses as well as enable developing strategies to improve customer satisfaction{{What is customer satisfaction?}}.
- Market research{{What is market research?}}: Text analysis can be used to analyse online reviews, social media posts, and other forms of customer feedback. This can help businesses understand consumer wants and attitude towards different products and services.
- Customer segmentation: Text analysis can be used to identify groups of customers with similar needs or preferences. This allows businesses to tailor their efforts to specific groups of customers. Techniques like clustering can be used to divide the text data into groups based on similarities. The business can then use the characteristics of each group to tailor their marketing or support efforts.
- Language & location identification: NLP techniques can be used to identify the language and location of text. This can improve content accuracy and relevance for applications like translation, geotargeting, and content recommendation.
- Content classification: Large volume of text data can be classified and categorized using text analysis. This can be useful for organizing and managing datasets and for identifying relevant information.
- Text summarization: Algorithms can summarize large datasets making it easier for businesses to quickly extract key insights and ideas.
- Trend identification: Large amount of text data can be analyzed to identify patterns and trends over time. This can be useful for identifying changes in public opinion, emerging topics, and seasonal trends.
- Intent identification: Conversations can be analyzed to identify the underlying reason or goal that a customer has when interacting with a business. This can be useful for improving customer experience, customer support, and identifying new product or service opportunities.
- Fraud detection: Algorithms can be trained to identify fraudulent activity by analyzing the language and content of digital communication.
- HR and talent management: Text analysis can be used to analyze resumes, job descriptions, and other text data to identify the right candidates. It can also be used to analyze employee feedback and performance reviews.
 Episode #14: The Complete Guide to AI-Powered Intent AnalysisREAD MORE
Episode #14: The Complete Guide to AI-Powered Intent AnalysisREAD MORE
The best text analysis method - Topic modeling
Topic modeling is used to identify the main topics or themes in a large dataset. It involves identifying patterns in the text data and grouping similar data together. Topic modeling is often used in combination with other techniques, such as text summarization and content classification, to extract insights and identify trends.
Topic modeling can be used to identify key terms that are most representative of each topic, and to generate a list of the most relevant text for each topic. This can be useful for organizing large datasets such as customer reviews, and for identifying the main topics of discussion.
Key elements of topic modeling in text analysis
There are several key elements of topic modeling in text analysis. They are used to identify the main topics or themes in a large dataset of text documents and to extract insights and trends from the data.
- Text corpus: The collection of documents that will be used for topic modeling. This could include customer reviews, online articles, or social media posts.
- Preprocessing: Topic modeling cannot be applied directly to text data, it requires preprocessing to remove unnecessary information and format the data for analysis. This can include tasks such as tokenization, stemming, and stop word removal.
- Term frequency-inverse document frequency (TF-IDF): TF-IDF is a statistical measure that calculates the importance of a term in a document, relative to the entire dictionary. It is commonly used in topic modeling to identify the most important terms and phrases that describe each topic.
- Latent Dirichlet allocation (LDA): LDA is a well-known algorithm that is used to find the main topics in a collection of text documents. It works by assuming that each document is a mixture of a small number of topics, and it employs statistical methods to determine the likelihood of each topic is present in the corpus.
- Topic representation: Once the topics have been identified, they can be represented in a variety of ways, such as as a list of key terms or as a visual representation of the most relevant documents for each topic.
 5 questions to answer about customer insightsREAD MORE
5 questions to answer about customer insightsREAD MORE

How to model topics for text analysis
There are several steps involved in modeling topics for text analysis:
- Preprocessing: This step is used to remove noise and prepare the dataset for analysis. It includes tasks such as tokenization, stemming, and stop word removal.
- Term frequency-inverse document frequency (TF-IDF): TF-IDF is a measure of the importance of a term within a document in relation to the entire dictionary. It is used to identify the key terms and phrases that are most representative of each topic.
- Algorithm selection: A wide variety of algorithms can be used for topic modeling, including LDA and non-negative matrix factorization (NMF). The appropriate choice is one that works for the size and complexity of the dataset and that meets the specific goals and objectives of the analysis.
- Model training: This process involves fitting the model to the data and adjusting the model parameters to optimize model performance.
- Topic identification: The trained model can be used to identify the key themes in the text data. This can be achieved by extracting the most significant terms and phrases that best describe each topic, and by clustering similar documents.
- Visualization and interpretation: The output of topic modeling can be represented in different formats, such as a list of essential terms or a visualisation of the most related documents. Interpreting the results is crucial to identify their significance in relation to the intended goals and objectives of the analysis.
Bottom-up topic modeling in text analysis
Bottom-up topic modelling identifies topics by grouping individual terms into larger, abstract concepts or topics, in contrast to the top-down approach, which starts with pre-defined topics and associates documents or terms.
Algorithms such as LSA, LDA, identify patterns and trends by analyzing relationships between individual terms. They can be used to identify the main topics in a dataset of text documents and to group similar documents together based on their content.
Bottom-up topic modeling can be useful for identifying hidden patterns and trends in large datasets of unstructured text data and for extracting insights and trends from the data. It is often used in combination with other text analysis techniques, such as text summarization and content classification, to extract insights and identify trends in large datasets of text data.
Top-down topic modeling in text analysis
Top-down topic modeling is an approach to identifying topics that involve starting with a pre-defined set of topics and identifying documents or terms that are most closely associated with each topic.
Algorithms such as hierarchical clustering and latent class analysis work by analyzing the relationships between individual terms and identifying patterns and trends in the data. They can be used to identify the main topics in a dataset of text documents and to group similar documents together based on their content.
Top-down topic modeling is handy for identifying patterns and trends in large, unstructured datasets and for extracting insights from the data. It is used in combination with text summarization and content classification to extract insights and identify trends in large datasets.

Best practices of modeling topics for text analysis
Here are some best practices for modeling topics for text analysis:
- Preprocessing: It is important to preprocess the data to remove noise.
- Choice of dataset: The text corpus should be chosen to make sure that it is relevant and contains enough information to generate meaningful topics.
- Choice of algorithm: There are various algorithms that can be used for topic modeling. It is important to select the algorithm that is appropriate for the size and complexity of the dataset and meets the specific goals and objectives of the analysis.
- Interpreting the results: The analysis results need to be interpreted and considered in relation to the objectives of the analysis.
- Visualizing the results: The results of the analysis can be visualized in many ways - a list of key terms or a visual representation of the most relevant documents for each topic.
- Validation: Topic modeling is an unsupervised algorithm, and results can be subjective, hence the need for validating the results with human experts.
- Fine-tuning: Continuously monitoring and fine-tuning the model based on the results and feedback obtained is necessary for its continued success.
How accurate does your text analysis need to be?
The required accuracy for text analysis algorithms depends on the objectives of the analysis and the consequences of errors. In some cases, where the results of the analysis will be used to make important decisions, high accuracy may be critical. In other cases, lower accuracy may be acceptable, as long as the results are still useful and provide meaningful customer insights{{Consumer insights}}.
The accuracy can also vary depending on the complexity of the data and the quality of the training data available. Some common tasks, such as text classification and sentiment analysis, can have relatively high accuracy levels, while others, such as language translation and text generation, can be more challenging and may have lower accuracy levels.
Text analysis in multiple languages
Text analysis can be carried out across different languages using a variety of approaches:
- Translation: The simplest approach is to translate the text data into a single language, e.g., English, and then analyze the translated data.
- Multilingual text analysis: Another approach is to use algorithms that are trained to handle multiple languages. These algorithms may have language-specific models or may be designed to handle multiple languages in a single model.
- Cross-lingual text analysis: Cross-lingual models identify patterns and trends in text across different languages. This is achieved using translation algorithms or multilingual models, or a combination of the two.
Tools for text analysis
A variety of software can be useful for text analysis, depending on the objectives of the analysis and the characteristics of the data. Some essential, general-purpose software may include:
- Programming language: A programming language, such as Python or R, is essential for developing custom text analysis algorithms. The also provide access to a wide range of readymade libraries and frameworks.
- Spreadsheet software: Spreadsheet software, such as Excel or Google Sheets, can be useful for basic preprocessing tasks.
- Data visualization tools: Tools such as Tableau can be useful for creating interactive visualizations of data, such as word clouds and sentiment analysis charts.
- NLP library: An NLP framework, such as NLTK or spaCy, can be useful for setting up tasks such as tokenization, stemming, and part-of-speech tagging.
- ML library: A machine learning framework, such as scikit-learn or TensorFlow, can be useful for developing custom algorithms and for accessing a wide range of pre-made algorithms.
Apart from the above-mentioned general purpose software, a large number of software companies provide text analysis software suites catering to various use cases through a simplified user experience.
Why you should use text analytics in customer experience
Text analysis is important for CXM because it can help businesses understand how customers feel about their products and services, and to identify strengths and weaknesses. By analyzing customer feedback, businesses can get a better understanding of customer sentiment around their products. This information can be leveraged to improve customer experience.
Text analysis can also be used to identify common themes or issues that customers are concerned about. This can help businesses identify opportunities for improvement and to make data-driven business decisions.
Businesses can use text analysis to identify groups of customers with similar needs and preferences, allowing them to tailor their efforts to specific groups. Clustering techniques can be used to divide text data, and the characteristics of each group can inform targeted marketing or support efforts.
Lastly, text analysis techniques can be used for identifying and tracking patterns and trends over time, which can be useful for identifying potential problems before they become significant.

Why Sprinklr is the best text analysis software
Sprinklr offers a variety of products aligned to different aspects of the text analysis value chain. Through its product suites, Sprinklr is able to support the following:
- Widest source coverage: Sprinklr's customers have access to the widest source coverage, including popular social media platforms (Facebook, X, formerly Twitter, Reddit, Instagram, YouTube), as well as over 100 million+ web sources (blogs, forums, and news websites). Additionally, through Sprinklr's Product Insights{{Product Research Tool}}, customers get access to 600+ premium review sources with full historical coverage. Customers can also easily connect internal data sources for analysis within Sprinklr. This allows businesses to get a holistic view of what is being said about their brand and industry, and to identify trends and insights that can inform their business strategies.
- Best-in-class sentiment analysis: Sprinklr's sentiment analysis capabilities allow businesses to track and monitor the sentiment of customer conversations over time and to identify changes in customer sentiment. Sprinklr’s sentiment analysis model supports 100+ languages to provide a well-rounded global view of conversations.
- Granular insights through Product Insights: Sprinklr’s Product Insights provides advanced analytics capabilities at the phrase-level, including sentiment analysis, category classification, and entity detection.
- Verticalized AI models: All Product Insights AI models are verticalized - specialized for a specific industry/ product segment - enabling customers to dig deeper into consumer conversations and identify actionable insights.
- Simplified reporting: Sprinklr provides access to a wide variety of standard dashboard and reporting templates that cater to the most common use cases. Users can also create custom dashboards using Sprinklr’s library of 45+ chart types to create visualisations for their unique needs.
- Dedicated data science team: Sprinklr’s products are developed using a staff of over 200+ ML engineers and data scientists. This deep domain expertise enables Sprinklr to create best-in-class AI models, leading to improved model performance.
- SaaS solution: Sprinklr is a true SaaS solution that is deployed on the cloud and available to customers through a web-based interface. This provides Sprinklr users a high degree of flexibility and scalability.
- Advanced capabilities: Sprinklr offers advanced AI{{Sprinklr Intution}} and NLP capabilities, such as trend detection, audience insights, text summarization, and descriptive and prescriptive insight identification, as part of its product suite, enabling customers to gather deeper business insights from their text data.
Sprinklr's text analysis capabilities can be used to identify trends and patterns in customer feedback and to understand how customers feel about a company's products or services. This can be useful for identifying opportunities for improvement and for making data-driven decisions about how to enhance the customer experience.

Frequently Asked Questions
Text analysis involves collecting the text data, preprocessing the data, extracting relevant features or variables from the data, and applying statistical or machine learning techniques to analyze and interpret the data. The specific steps will depend on the goals and techniques being used for the analysis.
Text analysis can be used by businesses to gain insights from customer feedback, identify trends and patterns in market research data, identify customer segments for targeted marketing, and automate processes such as customer service inquiries.
Some common types of text analytics include sentiment analysis, topic modeling, keyword extraction, and natural language processing (NLP). These techniques can be used to understand customer sentiment, identify trends and patterns in data, extract key information from documents, etc.
