How are Product Insights models trained?
Updated
Sprinklr starts to build the model by collecting unclassified raw data from various channels. The raw data is then segregated into unsupervised clusters. These clusters are used to identify the key categories of conversation which leads to the taxonomy creation. Unclassified mentions are annotated against the taxonomy by native-language speakers to ensure accuracy. Once the model is trained, it finds natural patterns in data and generates insights.
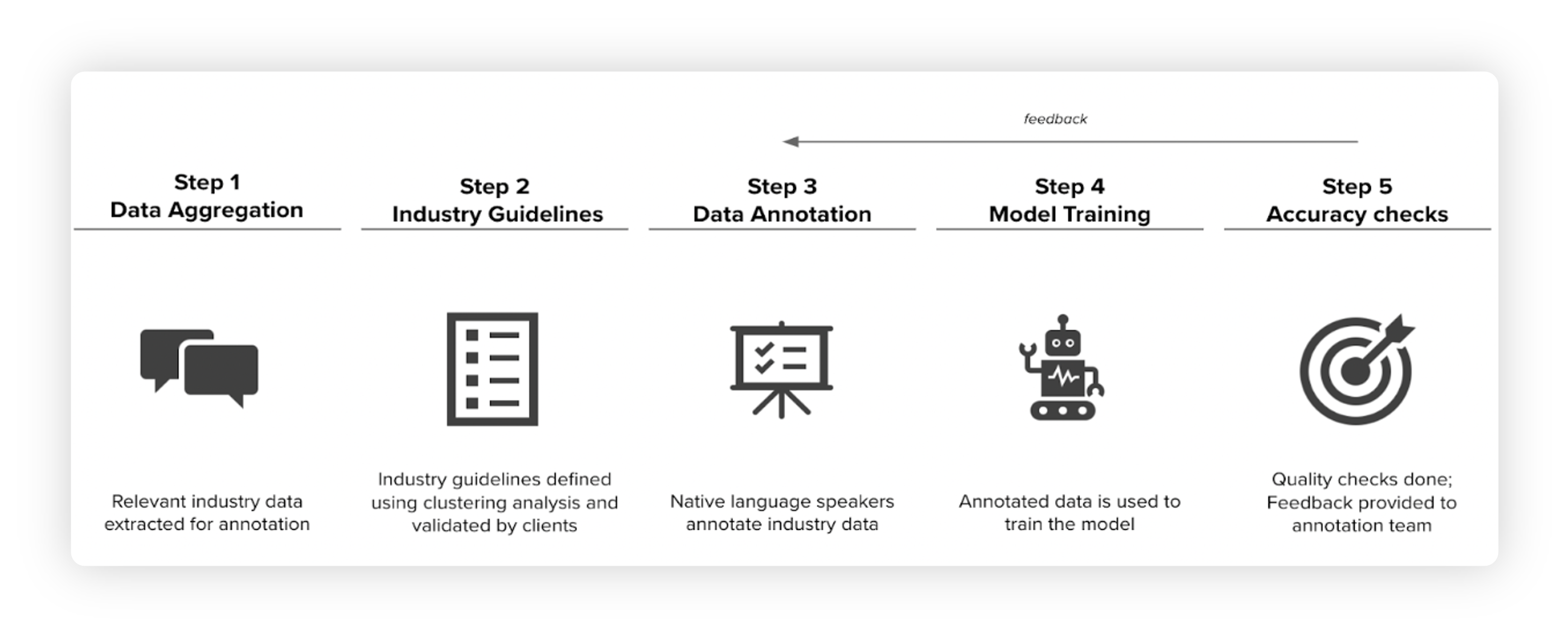
Data aggregation
Sprinklr collects unclassified raw data like comments, mentions, tags, etc. The data is collected in line with the channels that will be analyzed by the model, i.e., the key sources of feedback for the client’s brands and products.
Industry guidelines
The raw data is grouped into unsupervised clusters. These clusters are then analyzed by Sprinklr’s industry experts and validated by the client to finalize the model taxonomy.
Data annotation
The data is manually annotated by native language speakers to ensure a highly accurate model. Sprinklr’s annotation team is globally distributed to ensure that each data point in the training data set is annotated by native speakers of the specific language.
Model training
The data annotation team works in collaboration with Sprinklr’s data science team to train the model using best-in-class tools and algorithms.
Accuracy checks
Stringent checks and validations are part of the standard playbook for model training to ensure accuracy. Data scientists provide feedback to annotators over multiple iterative cycles to drive model accuracy.