Classify messages and train the new model
Updated
This section aims to provide a comprehensive guide on creating a new model training project for Sprinklr's Text Classifier that can filter out irrelevant terms for your brand or industry without any manual rule implementation or keyword maintenance. The article will walk you through the entire workflow.
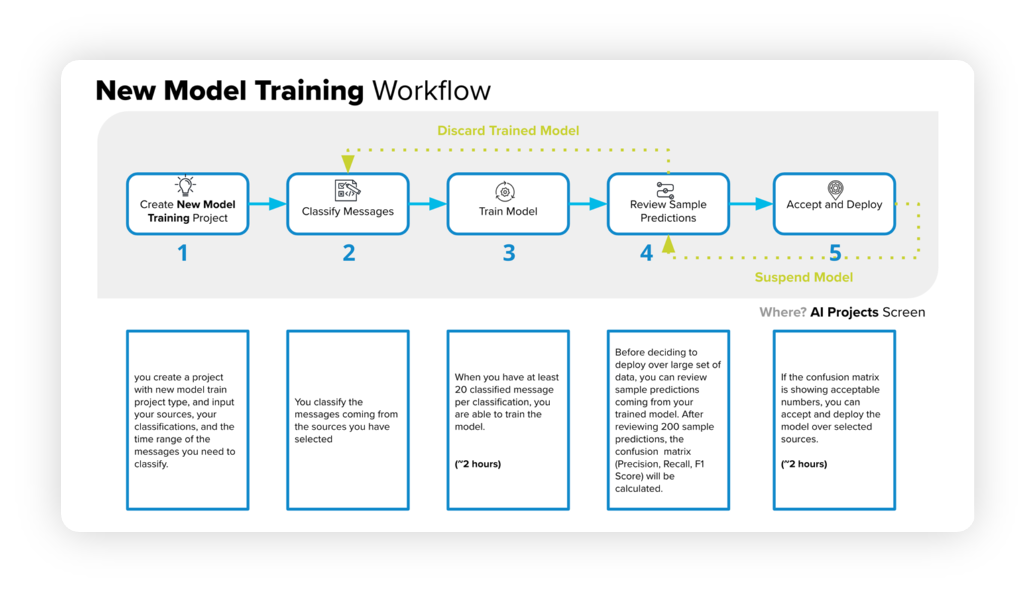
The below diagram will help you understand the New Model Training Workflow –
![]() Enablement note: Use of this feature requires that AI Studio be enabled in your environment. AI Studio is a paid module, available on demand. To learn more about getting this capability enabled in your environment, please work with your Success Manager.
Enablement note: Use of this feature requires that AI Studio be enabled in your environment. AI Studio is a paid module, available on demand. To learn more about getting this capability enabled in your environment, please work with your Success Manager.
The model training workflow consists of several steps that we will discuss in the following sections –
Begin by creating a new project, specifying sources, classifications, and a time range.
Classify messages from the chosen sources.
Train the model using a minimum of 20 classified messages per classification, which can take around 2 hours.
Examine sample predictions to generate a confusion matrix, including precision, recall, and F1 score.
If the confusion matrix meets the desired criteria, approve and deploy the model, which can take approximately 2 hours.
If the matrix is unsatisfactory, cancel and re-classify the messages.
Classifying text messages
The following steps describe how to classify text messages after creating a new text classifier project in AI Studio –
Go to the AI Projects window and click the Options icon next to your project. Then select Classify Messages.
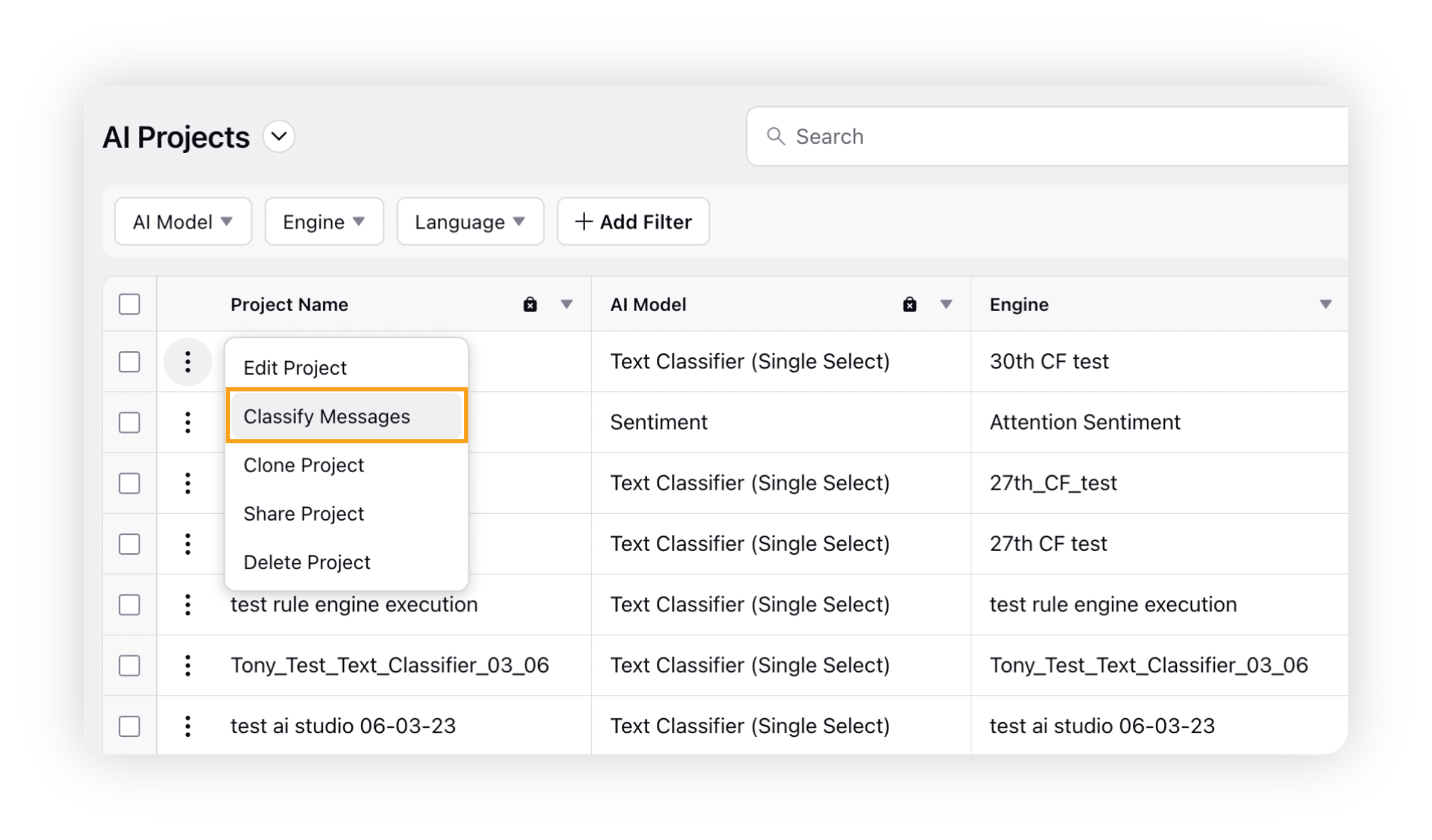
This will take you to the Classify Text Messages window where you can create your training dataset by classifying messages.
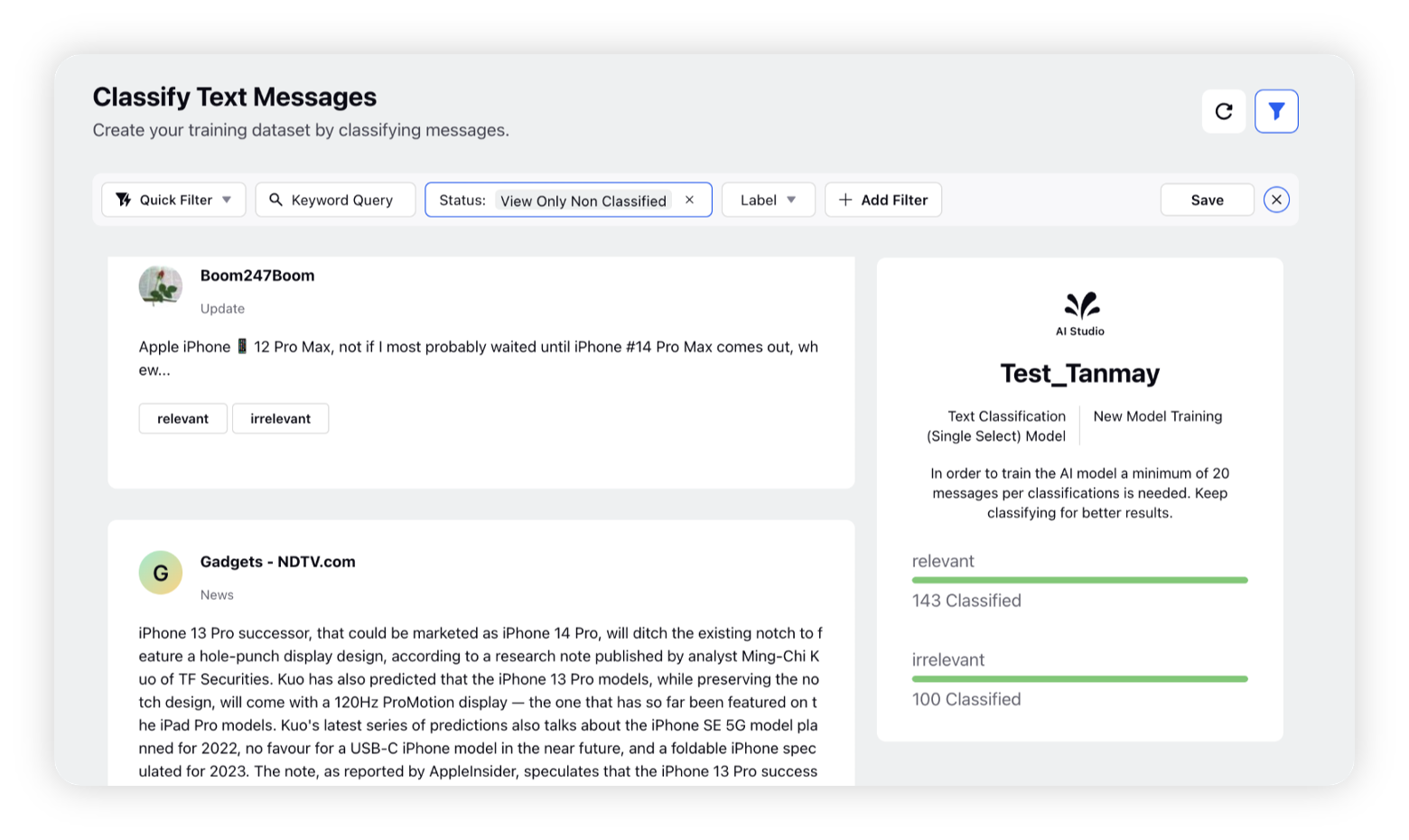
All the messages matching the criteria you selected earlier (during project creation) will appear with the respective classification values input in Step 2. You can use the filter bar to filter unclassified or classified messages as per your requirement.
At least 20 messages must be classified for each category to train the model. The more messages you classify, the better the model will perform. For more information, refer to the Pre-processing section.
You can use different options to filter messages, such as View All, View Only Classified, and View Only Non-Classified. Additionally, you can filter messages using the categories you have created.
Once you classify the required number of messages, a Train Model button will appear, allowing you to proceed with training the model.
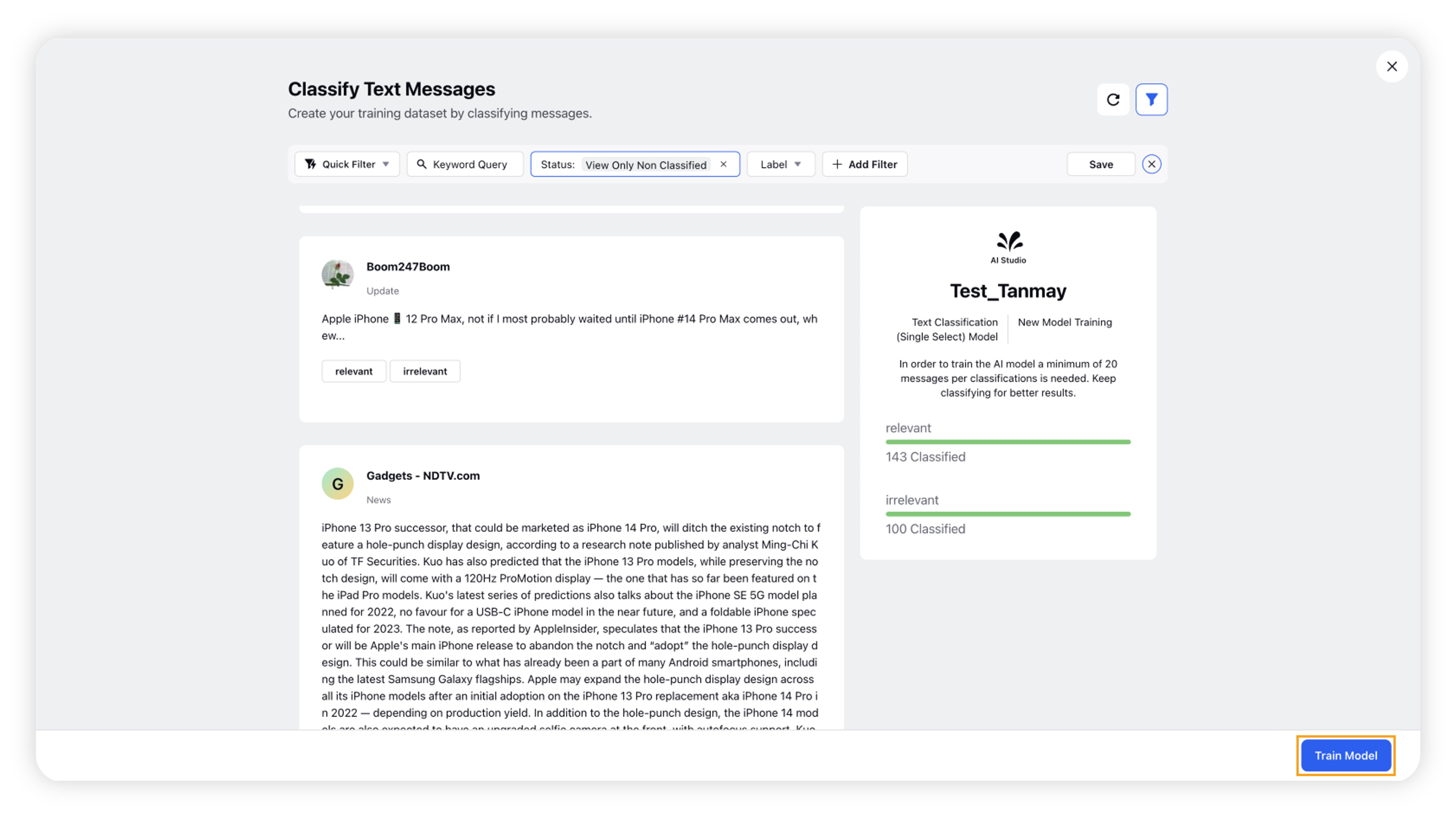
You can either proceed with Model Training now by clicking on the button or classify more messages.
 Note: In case you make a mistake while classifying messages and want to remove a message from your training dataset, you can easily undo your classification by clicking on the classification value. This will declassify the message.
Note: In case you make a mistake while classifying messages and want to remove a message from your training dataset, you can easily undo your classification by clicking on the classification value. This will declassify the message. After you finish classifying the messages and click the Train Model button, the AI Model will start the training process. You will need to wait until the training process is completed.
The model's status will change from Training Queued to In Training and finally to Ready for Deployment.
Once the AI Model is ready, you can begin reviewing and approving the sample predictions.
Pre-processing
It is worth noting that the system performs several pre-processing tasks on the backend to clean and standardize the messages. These tasks typically involve removing hashtags, emojis, multiple spaces, and punctuation marks, among other things.
Once the pre-processing tasks are complete, the system then removes any duplicate messages. This means that two distinct messages that have the same text but different emojis, for example, will eventually be considered duplicates after pre-processing and removed from the dataset. Examples are given below –
Saving for a trip to Disney! $AmazonFindOfTheMonth #savings 🥰😘
Saving for a trip to Disney! $AmazonFindOfTheMonth #savings 😇😍
It is important to keep this in mind when classifying the data, as the removal of duplicates can impact the final set of messages. However, by removing duplicates, we can ensure that the data is clean and standardized, which is essential for accurate analysis and modelling.
Best practices
Try to classify a variety of messages that are sufficiently distinct from each other. Messages that are identical except for their emojis, for example, are not considered unique enough for training purposes.
Ensure that you have enough classified messages for each category so that the model can be trained on a representative set of data.